Continuous Distance dependent Level of Detail for Rendering Heightmaps
用于渲染高度图的连续距离相关的LOD技术
英文paper及源码: https:// github.com/fstrugar/CDL OD
概要
本文介绍了一种基于 GPU 的高度图地形渲染技术,它是对现有几种方法的改进,并带有一些新的想法。它类似于地形clipmap方法 [Tanner et al. 98, Losasso 04],因为它直接从源高度图数据中绘制地形。然而,它不是使用一组规则的嵌套网格,而是围绕规则网格的四叉树构建的,更类似于 [Ulrich 02],它提供了更好的细节层次分布。该算法相对于以前技术的主要改进是,LOD 函数在整个渲染网格中是相同的,并且基于观察者和地形之间的精确 3 维距离。为了实现这一点,我们使用了一种处理 LOD 级别之间转换的新技术,它可以提供平滑和准确的结果。由于这些原因,该系统更加可预测和可靠,具有更好的屏幕三角形分布、更清晰的关卡过渡,并且无需拼接网格。这也简化了与游戏和模拟应用程序中常见的其他 LOD 系统的集成。在性能方面,与类似的基于 GPU 的方法相比,它仍然具有优势,并且适用于支持 Shader Model 3.0 及更高版本的所有图形硬件。演示和完整的源代码可在免费软件许可下在线获得。
介绍
高度图显示和交互是游戏和模拟图形引擎的常见要求。 渲染地形的最简单方法是蛮力方法,其中源高度图数据中的每个纹素都由三角形规则网格中的一个顶点表示。 对于较大的数据集,这是不切实际或不可能的:因此需要细节级别 (LOD) 算法。 LOD 系统会产生不同复杂度的网格,通常是观察者距离的函数,因此屏幕上的三角形分布相对相等,同时仅使用数据和渲染资源的子集。
从历史上看,这些算法是在 CPU 上执行的。 一个很好的例子是经典的学术算法 [Duchainea et al. 97]。 但是,由于 GPU 的原始(主要是并行)处理能力比 CPU 的改进速度快得多,为了使整个系统得到最佳使用,地形渲染算法已更改为尽可能多地利用图形硬件。
目前,在现代 PC 和游戏机架构的背景下,如果无法为硬件图形管道提供足够的三角形或使用过多的 CPU 处理能力,那么在 CPU 上产生最佳三角形分布的算法几乎没有什么好处。 CPU 和 GPU 之间的 API、驱动程序和 OS 层也是一个常见的瓶颈,如 [Wloka 03] 中所述。 因此,即使是简单的基于 GPU 的方法也可以比那些在 CPU 上执行且以前被认为是最佳的复杂方法更快并提供更好的视觉效果。
这种趋势的第一个例子是 [de Boer 00] 中给出的算法,虽然它本质上仍然是一种基于 CPU 的算法,但其目的是产生一个具有较少优化分布但执行成本较低的高三角形输出 [Duchainea et 人。 97],从而在早期的专用图形硬件上运行时提供更好的结果。
后来 [Ulrich 02] 开发了第一个完全面向 GPU 的算法,由于其良好的细节分布和优化的镶嵌网格,它仍然是在现代硬件上渲染地形的绝佳选择。 它的缺点是涉及冗长的预处理步骤,无法实时修改地形数据,以及有点不灵活和不太正确的 LOD 系统。
有时更喜欢更简单的基于高度图的方法。 最受欢迎的之一是 [Asirvatham 等人。 05]及其各种改进。
本文提出了一种技术,该技术基于使用在顶点着色器中置换的固定网格网格来直接从高度图数据源渲染地形,同时处理 [Ulrich 02] 和 [Asirvatham 等人发现的一些缺点和复杂性。 人。 05] 通过使用基于四叉树的结构和新颖的、完全可预测的连续 LOD 系统。 该技术旨在提供一种在 Shader Model 3.0 及更高版本的图形硬件上渲染基于高度图的地形的最佳方式; 该技术可以通过硬件细分支持进行扩展,以充分利用最新的 Shader Model 5.0 生成功能。
LOD方法
clipmaps算法的一个主要缺点 [Asirvatham 等人。 05]是细节层次本质上是基于观察者位置的二维(x;y:纬度,经度)分量,而忽略了高度。这会导致网格复杂度分布不均和锯齿问题,例如,当观察者位于网格上方时,下方的细节级别仍然比所需的要大得多,反之亦然。这在 [Asirvatham 等人中仅部分解决。 05] 通过考虑当前观察者在地形之上的高度,并在需要时降低更高的 LOD 级别。
另一方面,[Ulrich 02] 使用在整个块(网格块)上相同的 LOD 函数,仅提供近似的基于三维距离的 LOD。
在现代游戏或模拟系统中经常遇到的场景中,这种近似可能会受到限制,在这些场景中,地形通常非常不平坦,并且观察者的高度和位置变化很快,因为它会产生不良的细节分布或运动引起的渲染伪影。它还会导致与其他渲染系统的集成困难,其中一些渲染系统本身使用细节级别优化,因为不可预测的地形 LOD 会导致渲染错误,例如不需要的交叉或放置在地形上的对象的浮动。
此处介绍的连续距离相关级别细节 (CDLOD) 技术通过提供 LOD 分布来解决这些问题,该 LOD 分布是所有渲染顶点的三维距离的直接函数,因此是完全可预测的。
LOD过渡
[Ulrich 02] 和 [Asirvatham 等人的技术的另一个缺点。 05]是LOD级别之间的不连续性需要额外的工作来消除间隙并提供平滑的过渡。 这可以通过在不同 LOD 级别之间使用额外的连接("拼接")条来解决。 这些条带除了增加渲染成本外,还会导致渲染阴影贴图时出现伪影等各种问题; 透明渲染地形时不需要的过度绘制(这是渲染地形水或类似效果时的问题); 等等。
此外,由于 LOD 级别之间的网格交换发生在具有不同三角形数量和形状的网格之间,因此如果使用任何基于顶点的效果(例如顶点照明),顶点输出插值的差异将导致出现跳变问题。 这也使其成为不太适合硬件细分的平台。
CDLOD 技术本质上避免了这些问题,因为用于在 LOD 级别之间转换的算法在实际交换发生之前将较高级别的网格完全转换为较低详细级别的网格。 这确保了完美平滑的过渡,没有接缝或伪影。 此外,渲染本身比 [Asirvatham et al. 05]更简单,因为只需要一个矩形规则网格来渲染所有内容。
数据组织和流式传输
可以像使用其他技术一样存储、压缩和流式传输地形数据,无需特别注意。 虽然这个主题超出了本文的范围,但它是任何实际的大型地形渲染系统实现的必要部分。 因此,StreamingCDLOD 演示提供了具有完整数据流的示例 CDLOD 实现。
算法实现
概述
CDLOD 将高度图组织成四叉树,用于在运行时从不同的 LOD 级别中选择合适的四叉树节点。选择算法以这样一种方式执行,即无论与观察者的距离如何,都能提供大致相同数量的屏幕三角形复杂度。
实际渲染是通过仅使用一个唯一的网格渲染选定节点覆盖的区域、读取顶点着色器中的高度图并相应地置换网格顶点来执行的。
更复杂的网格可以在顶点着色器中平滑地变形为不太复杂的网格,以便在超出范围时可以无缝地替换为较低分辨率的网格,反之亦然。
四叉树结构是从输入高度图生成的。它具有恒定的深度,由内存和粒度要求预先确定。一旦创建,四叉树就不会改变,除非源高度图发生变化。每个节点都有四个子节点,并包含它所覆盖的矩形高度图区域的最小和最大高度值。提供的示例 BasicCDLOD 使用简单的显式四叉树实现,其中所有必需的四叉树数据都包含在节点结构中。 StreamingCDLOD 示例实现了一个更高级的版本,其中算法仅依赖于(部分压缩的)最小/最大图,而所有其他数据都是隐式的,并在四叉树遍历期间生成。此版本使用的内存要少得多,但稍微复杂一些。
四叉树和节点选择
渲染过程的第一步是四叉树节点选择。 它在观察者每次移动时执行,这通常意味着在每一帧期间。
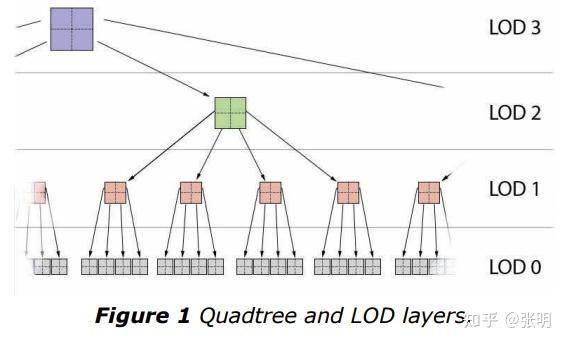
LOD距离和变形区域
为了知道在哪里选择哪些节点,在执行节点选择过程之前预先计算每个 LOD 层覆盖的距离。 这些计算的目标是在整个渲染地形上每平方屏幕单位产生大致相同的平均三角形数量。
由于算法设计将每个连续 LOD 级别之间的复杂度差异固定为 4,假设使用三维投影变换 渲染(由于投影变换的工作方式)。
这样就创建了 LOD 范围数组(参见图 2),每个级别的范围是前一个级别的两倍,而最终级别的范围(最大、最不详细)表示所需的总观察距离。
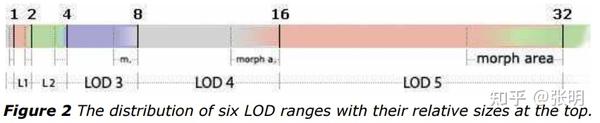
为了提供平滑的 LOD 过渡,还定义了变形区域,标记了较高复杂度的网格将变形为较低复杂度的范围。 这个变形区域通常覆盖每个 LOD 范围的最后 15%-30%。
四叉树遍历和节点选择
一旦计算出 LOD 范围数组,它就会用于创建代表当前可观察地形部分的节点选择(子集)。 为此,四叉树从最低详细级别的最远节点开始递归遍历,一直到最近、最详细的节点。 然后,此选择包含渲染地形所需的所有动态元数据。
以下 C++ 伪代码说明了该算法的基本版本:
// Beginning from the LODLevelCount and going down to 0; lodLevel 0 is the highest detailed level. bool Node :: LODSelect ( int ranges [], int lodLevel , Frustum frustum ) { if ( ! nodeBoundingBox . IntersectsSphere ( ranges [ lodLevel ] ) ) { // no node or child nodes were selected; return false so that our parent node handles our area return false ; } if ( ! FrustumIntersect ( frustum ) ) { // we are out of frustum, select nothing but return true to mark this node as having been // correctly handled so that our parent node does not select itself over our area return true ; } if ( lodLevel == 0 ) { // we are in our LOD range and we are the last LOD level AddWholeNodeToSelectionList ( ); return true ; // we have handled the area of our node } else { // we are in range of our LOD level and we are not the last level: if we are also in range // of a more detailed LOD level, then some of our child nodes will need to be selected // instead in order to display a more detailed mesh. if ( ! nodeBoundingBox . IntersectsSphere ( ranges [ lodLevel - 1 ]) ) { // we cover the required lodLevel range AddWholeNodeToSelectionList ( ) ; } else { // we cover the more detailed lodLevel range: some or all of our four child nodes will // have to be selected instead foreach ( childNode ) { if ( ! childNode . LODSelect ( ranges , lodLevel - 1 , frustum ) ) { // if a child node is out of its LOD range, we need to make sure that the area // is covered by its parent AddPartOfNodeToSelectionList ( childNode . ParentSubArea ) ; } } } return true ; // we have handled the area of our node } } 选择一个节点包括存储它的位置、大小、LOD 级别、部分选择的信息以及其他数据(如果需要)。 这将保存在稍后用于渲染的临时列表中。
每个节点只能在其四个子节点中的一些子节点的区域上部分选择。 这样做是为了如果只有少数子节点在其 LOD 范围内,则不需要渲染所有子节点,从而允许在 LOD 级别之间进行更早的交换,从而提高算法性能和灵活性。
节点在遍历四叉树时也会被截断,消除了不可见节点的渲染。 渲染阴影贴图或类似效果时,视锥体剔除基于阴影相机,但实际 LOD 选择仍应基于主相机设置。 这样做是为了避免由于两个不同的 LOD 函数(对于阴影贴图相机和主相机)导致的地形网格差异而导致的渲染错误。

由于 LOD 图层选择基于与观察者的实际三维距离,因此它适用于所有地形配置和观察者高度。 如图 3 和图 4 所示,这会在各种场景中产生正确的细节复杂性和更好的性能。

渲染
为了渲染地形,我们遍历选定的节点,它们的数据用于渲染它们所覆盖的地形补丁。 LOD 级别之间的连续过渡是通过将每一层的区域变形为不太复杂的相邻层来实现的,以实现它们之间的无缝过渡(参见图 5)。

渲染非常简单:在顶点着色器中转换固定尺寸的单个网格网格以覆盖世界空间中的每个选定节点区域,并使用纹理提取来置换顶点高度,从而形成特定地形补丁的表示。 常用的网格尺寸为 16x16、32x32、64x64 或 128x128,具体取决于所需的输出复杂度。 一旦选择,此网格网格分辨率是恒定的(即,对于所有节点都相等),但可以在运行时更改,这可以方便地以较低分辨率渲染地形以获得需要较少细节的效果,例如反射、辅助视图、低 质量阴影等
变形实现
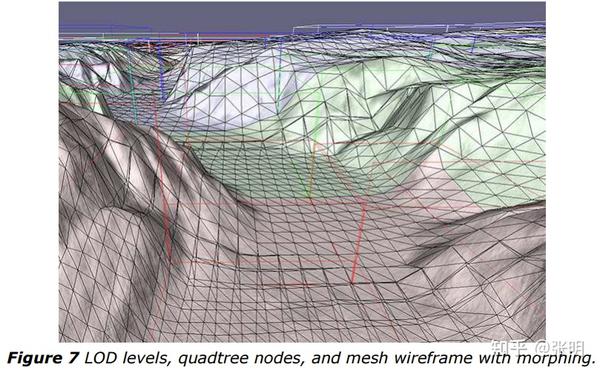
使用 CDLOD,每个顶点根据其自己的 LOD 度量单独变形,这与 [Ulrich 02] 中的方法不同,其中变形是按节点(按块)执行的。 每个节点都支持两个 LOD 层之间的转换:它自己的层和下一个更大且不太复杂的层。 在顶点着色器中执行变形操作,通过逐渐放大两个三角形并缩小其余六个三角形,将来自更详细网格的每个八个三角形块平滑地变形为不太详细网格上的两个三角形的相应块 三角形变成未光栅化的退化三角形。 此过程产生没有接缝或 T 形接头的平滑过渡(参见图 6 和图 7)。

首先,计算观察者和顶点之间的近似距离以确定所需的变形量。 用于计算此距离的顶点位置可以是一个近似值,只要近似函数在整个数据集域上是一致的。 这是必要的,因为为了防止接缝,节点网格边缘上的顶点必须与相邻节点上的顶点完全相同。 在我们的例子中,x(纬度)和 y(经度)分量总是正确的,因为使用相同的函数将它们拉伸到世界空间,但是 z(高度)必须是近似的,或者使用一致的过滤器从高度图中采样 .
示例代码中的变形值 morphK 介于 0(无变形,高细节网格)和 1(完全变形,三角形减少四倍)之间,用于将每个变形网格顶点逐渐移向相应的无变形顶点。 变形顶点定义为一个网格顶点,其网格索引 (i, j) 中的一个或两个为奇数,其对应的非变形邻居是坐标为 (i – i/2, j – j/ 2)。
以下是用于变形顶点的 HLSL 代码:
// morphs input vertex uv from high to low detailed mesh position // - gridPos: normalized [0, 1] .xy grid position of the source vertex // - vertex: vertex.xy components in the world space // - morphK: morph value const float2 g_gridDim = float2 ( 64 , 64 ); float2 morphVertex ( float2 gridPos , float2 vertex , float morphK ) { float2 fracPart = frac ( gridPos . xy * g_gridDim . xy * 0.5 ) * 2.0 / g_gridDim . xy ; return vertex . xy - fracPart * g_quadScale . xy * morphK ; } 最后,通过使用双线性过滤器(仅对变形区域中的顶点需要过滤)使用从 x 和 y 分量计算的纹理坐标对高度图进行采样来获得 z 分量。 当一个节点的所有顶点都变形到这种低细节状态时,网格实际上包含的三角形数量减少了四倍,并且与较低 LOD 层中的三角形完全匹配; 因此它可以被它无缝替换。
设置
需要仔细选择用于生成四叉树和运行算法的设置,以匹配地形数据集特征,同时提供最佳性能。 在随附的示例中,每个数据集都定义了自己的设置。 以下是最重要的简要说明:
LeafQuadTreeNodeSize 设置决定了高度图栅格大小中四叉树的深度(粒度),而 LODLevelCount 定义了 LOD 级别的数量。使用更多 LOD 级别可提供更远的观看距离和更好的 LOD 分布,但会降低性能并增加内存使用。 LeafQuadTreeNodeSize 的较小值允许更大范围的查看距离和更好地处理非常不平坦的地形,但会增加四叉树内存使用和批处理计数 [Wloka 03]。这两个值在导出阶段设置并在运行时保持固定。
RenderGridResolutionMult 定义了用于渲染地形的静态网格网格的分辨率——它影响三角形输出,但不会以任何其他方式改变算法行为。它是一个方便的工具,可以在运行时轻松平衡渲染质量和算法性能。
视图距离也可以在运行时变化,用于更改最大渲染距离和细节级别。与 RenderGridResolutionMult 不同,更改它会影响 LOD 范围、节点选择,从而影响渲染批次的数量、所需的流数据等。
粒度问题
该算法的一个限制是单个四叉树节点只能支持两个 LOD 层之间的转换。这限制了最小可能的查看范围或最小四叉树深度,因为在同一节点区域上的两个 LOD 层之间只能执行一次平滑过渡。增加查看范围将使 LOD 过渡区域彼此远离,并以处理更多渲染数据为代价来解决问题。其他选项是减少 LOD 级别的数量,这会降低 LOD 系统的好处,或者增加四叉树深度以增加粒度,这会增加四叉树内存和 CPU 使用率。也可以减小变形区域的大小以缓解此问题,但这会使级别之间的过渡变得明显。
由于 LOD 在三个维度上工作,因此当使用高度差很大的极其粗糙的地形时,这个问题将得到加强:因此,每个数据集可能需要不同的设置。
在提供的数据示例中,调整了 LOD 设置,以便始终可以接受范围。在使用不同数据集和设置的情况下,这些 LOD 过渡问题可能会以 LOD 级别之间的接缝形式出现。演示代码的调试版本将始终检测到这种情况的可能性并显示警告以便可以更正设置(检测代码过于热心,因此警告并不能保证接缝是可观察到的 - 只是理论上可能)。
流式传输和最佳四叉树数据存储
大型地形渲染算法的任何实际实现还必须提供在工作内存中仅保留所需地形数据集的子集的机制。 这个子集通常是从观察者的角度渲染地形所需的最小值,并且随着观察者的位置变化而加载(流式传输)进出。 虽然流式传输主题的详细讨论 10 超出了本文的范围,但将涵盖一些基础知识。 如果需要,StreamingCDLOD 实现会提供所有必要的实现细节。
CDLOD 技术需要存储两个单独处理的数据集:
• 四叉树数据,这是 LOD 算法工作所需的元数据。
• 地形数据,地形数据,这是渲染所需的实际数据,由高度图、法线图、叠加图像等组成。
四叉树数据
BasicCDLOD 实现中的四叉树数据是节点结构的一部分。由于每个节点都包含定义其大小、位置、指向其兄弟节点的指针等数据,因此使用了大量不必要的内存。 StreamingCDLOD 实现通过仅保留必要的 minZ 和 maxZ 值来避免这种情况,这些值描述了节点覆盖的高度图区域的最小和最大高度值。其余数据是在四叉树遍历期间自动生成的,需要额外的少量计算成本和非常高(大约 30 倍)的内存节省。
为了存储这个最小/最大数据,每个 LOD 级别使用两个无符号 16 位整数值的二维矩阵:为相应四叉树级别的每个四叉树节点设置一个二值集。因此,最详细的 LOD 级别 0 的矩阵尺寸为 [HeightmapWidth/LeafQuadTreeNodeSize, HeightmapHeight/LeafQuadTreeNodeSize],每个下一个 LOD 级别需要的最小/最大数据少四倍。
为了进一步提高内存使用率,通过将最小/最大值存储在父节点的最小/最大值的归一化空间中来压缩最详细的 LOD 级别矩阵,可以使用无符号 8 位整数存储,精度损失很小。与 BasicCDLOD 实现中的幼稚实现相比,这将内存使用量减少到大约 1/45,并且接近理论上可能的最大值。
这个最小/最大矩阵代表了 CDLOD 算法所需的所有数据(除了实际的高度图)。由于与其他地形数据相比它很小,StreamingCDLOD 实现将整个最小/最大矩阵保存在内存中。例如,使用 32K x 32K 字节的源高度图和大小为 32 的叶四叉树节点渲染地形需要大约 3.5 MiB 的内存。
地形数据
地形数据(高度图、法线贴图、叠加图像等)被拆分为每个 LOD 层的可流式块,并且可以选择压缩。 在某些情况下,纹理块可能需要与相邻的块略微重叠,以避免由于边缘上的纹理过滤而在区域边界附近呈现伪影。
在运行时,用于渲染的相同 LOD 选择算法也用于选择范围内的节点,然后用于将数据块标记为潜在可见并相应地将它们流入或流出。 流数据块粒度通常比四叉树粒度小很多,因此一个数据块包含许多四叉树节点的数据。 可以使用不同的流式 LOD 设置来平衡更高质量的渲染和更低的内存使用。
示例代码
提供了两个示例项目:BasicCDLOD 和 StreamingCDLOD。 这两个项目都是用 C++ 编写的,使用 DirectX9 和 HLSL,并且应该可以在大多数支持顶点着色器纹理采样的 GPU 上运行,即支持 Shader Model 3.0 的那些。
BasicCDLOD 以其基本形式实现 CDLOD 技术。 StreamingCDLOD 以实际可用的形式实现 CDLOD 技术,具有更优化的基本算法内存使用和简单的数据流。
源代码在 Zlib 许可下分发; 请参阅本文末尾的下载链接。
性能
此处介绍的性能测量是使用算法的 StreamingCDLOD 实现获得的。
与其他类似的基于 GPU 的技术一样,CDLOD 的性能将受到 GPU 执行顶点着色器和/或光栅化三角形的能力的限制。 尽管在顶点着色器中采样纹理可能非常昂贵,但由于良好的屏幕三角形分布,此成本通常不是主要限制因素,这确保了不需要非常高的三角形数即可获得良好的视觉质量。
比较
与 [Asirvatham 等人的方法相比。 05],CDLOD 产生更高质量的三角形分布和利用率,更少或没有渲染伪像,以及相似的三角形输出和渲染批次计数 [Wloka 03]。 不利的一面是,四叉树存储需要增加少量内存成本。
另一方面,[Ulrich 02] 的算法在渲染预先计算的自适应细分地形网格时,在相似的视觉质量下具有潜在更高的 GPU 性能,但出于同样的原因,它比基于高度图的方法实用性要低得多。 它还遭受与 [Asirvatham et al. 05] 由于缺乏平滑的 LOD 分布,如简介中所述。
数据集
这些是用于测试的数据集:
• califmtns_large:48897 x 30465 高度图,带有法线贴图和简单的纹理喷溅技术;
• 夏威夷:13825 x 16769 高度图,带有法线贴图和叠加地形图
• puget:经典的"Puget Sound"16385x16385 高度贴图,没有法线贴图、没有动态光照、没有细节贴图和带有嵌入光照的叠加颜色贴图
用于测量的设置提供了质量和性能之间的平衡。 数据集足够大,可以真实地分析内存使用(尤其是 califmtns_large)和 CPU/GPU 性能; 增加源高度图/图像大小将成比例地增加 12 硬盘存储需求和四叉树内存使用(示例代码中没有流式传输),但不会显着影响总内存使用或 CPU/GPU 性能。
CPU性能
由于在 CPU 上不生成数据,并且每帧向 GPU 传输少量数据,因此该算法在几乎所有场景中本质上都受 GPU 限制。大部分所需的 CPU 时间被 DirectX9 渲染 API 调用消耗,而一小部分用于实际的 CDLOD 算法(四叉树遍历和数据选择)。每个 LOD 级别的通常渲染批次数为 10。演示数据集中使用七到九个 LOD 级别,平均每帧需要 60 到 120 个渲染批次来渲染地形。
表 1 显示了在三个不同 CPU 平台上四叉树遍历(连同流数据选择)和 DirectX9 渲染(如果适用)的一帧期间花费的典型 CPU 时间。
数据流的成本没有给出,因为它直接取决于观察者的移动、压缩算法和数据大小,并且通常无论如何都在单独的线程上执行(如 StreamingCDLOD 示例中)。
如前所述,DirectX9 渲染成本应仅用作指导,因为渲染代码不是非常优化,并且还可能因驱动程序、操作系统版本等而有很大差异。

GPU性能
GPU 的性能瓶颈要么是顶点纹理获取成本(用于地形顶点的置换),要么是三角形光栅化和像素着色器成本。 这主要取决于设置、GPU 硬件和显示分辨率。
表 2 显示了不同显示分辨率和不同数据集的典型帧速率(帧/秒)。 数据集 califmtns_large 和 hawaii 使用基于一个定向光和来自高分辨率法线贴图纹理的法线的光照显示,没有叠加纹理。 puget 数据集仅使用带有烘焙光照的叠加纹理。
测量是在 Core2 Duo 3.16Ghz 系统上进行的,但 NVidia ION 除外,它使用 1.66 GHz Atom 330 CPU。

内存使用
内存使用取决于四叉树粒度、流设置和数据。 更改导出器 LOD 设置和查看范围可以将内存使用更改一个数量级。 因此,必须注意在渲染质量和内存使用之间建立正确的平衡。 表 3 显示了演示数据集的典型内存使用情况。 数据包括高度图、法线贴图和图像叠加纹理,它们是使用默认设置和最坏情况下的观察者位置进行测量的。
用于运行解压和其他与地形渲染不直接相关的算法的内存没有给出,因为这样的使用会根据使用场景和实现细节而有很大差异。 这种额外的内存使用量通常大大低于表 3 中给出的四叉树和纹理内存使用量的组合。

额外的想法
硬件(基于 GPU)细分
新一代图形硬件(Shader Model 5)支持可编程的基于硬件的细分。 这可用于在渲染地形时提供两全其美的效果:自适应细分网格的性能和良好的视觉输出以及基于高度图的方法的灵活性。
由于 CDLOD 使用平滑连续的三角形变形来执行 LOD 层之间的过渡,没有不连续性或 T 形接头,因此可以轻松地在顶部应用额外的细分,而不会破坏使其成为硬件细分的良好平台的连续性。
旧硬件上的性能
在较旧的显卡(Shader Model 2 或更低版本)的情况下,顶点着色器中的高度图采样成本可能太高,甚至由于缺乏硬件功能而无法实现。在这种情况下,合并 CDLOD 和 ChunkedLOD [Ulrich 02] 技术是一种选择,其中可以在 CDLOD 框架中使用预先计算的自适应细分网格的好处,并具有类似的连续 LOD 算法的好处。
这可以通过预先计算一个镶嵌三角形网格、为每个连续的不太详细的 LOD 级别简化它并将其拆分为四叉树来实现。每个顶点都可以包含额外的变形数据,以便在 LOD 过渡期间,可以将一些顶点移动到顶点着色器中的相邻顶点,从而消除三角形并有效地将更详细的 LOD 网格变形为不太详细的 LOD 网格。这种技术提供了正确的基于连续三维距离的 LOD,消除了对拼接条的需要,并避免了 [Ulrich 02] 中的方法中存在的主要问题。
与基于高度图的方法相比,这种方法的缺点是冗长的数据预处理步骤、更困难的网格压缩以及可以进行实时地形修改的事实。
References
[Asirvatham et al. 05] A. Asirvatham, H. Hoppe. "Terrain Rendering Using GPU-Based Geometry Clipmaps. " In GPU Gems 2, edited by M. Pharr, pp. 27-45. Reading, MA: AddisonWesley, 2005.
[de Boer 00] Willem H. de Boer. "Fast Terrain Rendering Using Geometrical MipMapping. " Available at http://www. ipcode.com/tutorials/ge omipmaps.pdf , October 2000.
[Duchainea et al. 97] Mark Duchaineau, Murray Wolinsky, David E. Sigeti, Mark C. Miller, Charles Aldrich, and Mark B. Mineev-Weinstein. "ROAMing Terrain: Real-time Optimally Adapting Meshes. " Proceedings of the Eighth Conference on Visualization, pp. 81{88. Los Alamitos, CA:IEEE, 1997.
[Losasso 04] F. Losasso, H. Hoppe. "Geometry Clipmaps: Terrain Rendering Using Nested Regular Grids." ACM Transactions on Graphics, 23:3 (2004), 769-776.
[Tanner et al. 98] Christopher Tanner, Christopher Migdal, and Michael Jones. "The Clipmap: A Virtual Mipmap. " In Proceedings of the 25th Annual Conference on Computer Graphics, pp. 151-158. New York: ACM, 1998.
[Ulrich 02] Thatcher Urlich. "Rendering Massive Terrains Using Chunked Level of Detail Control. " SIGGRAPH 2002 Course Notes. San Antonio, TX: ACM, 2002.
[Wloka 03] M. Wloka "Batch, Batch, Batch: What Does It Really Mean? " NVIDIA. Available at http:// developer.nvidia.com/do cs/IO/8230/BatchBatchBatch.pdf , 2003.
Demos, code, data
Additional material can be found online:
Binaries and a small example dataset
http://www. vertexasylum.com/downlo ads/cdlod/binaries_tools_testdata.exe
Complete source code
http://www. vertexasylum.com/downlo ads/cdlod/source.zip
Example datasets
http://www. vertexasylum.com/downlo ads/cdlod/dataset_califmtns.exe ,
http://www. vertexasylum.com/downlo ads/cdlod/dataset_hawaii.exe ,
http://www. vertexasylum.com/downlo ads/cdlod/dataset_puget.exe
Example animations
http://www. vertexasylum.com/downlo ads/cdlod/cdlod_calif.wmv ,
http://www. vertexasylum.com/downlo ads/cdlod/cdlod_hawaii.wmv ,
http://www. vertexasylum.com/downlo ads/cdlod/cdlod_params.wmv
Paper revision 1
Originally published in the "journal of graphics, gpu and game tools":
http:// jgt.akpeters.com/papers /Strugar10/
Filip Strugar, filip.strugar@gmail.com, filip.strugar@rebellion.co.uk
Source: https://zhuanlan.zhihu.com/p/536751271
0 Response to "Continuous Distance dependent Level of Detail for Rendering Heightmaps"
Post a Comment